About
The Qur'an is composed of 114 surahs (~chapters) and over 6000 ayas (~verses). Unlike a traditional book, the Qur'an does not follow a single narrative but is rather a non-linear whole with many intermingling themes that repeat throughout its verses. This is why no single verse can be read on its own without understanding its broader context. Due to the nature of its composition, this context can be spread across multiple chapters rather than within a single place.
I built this web application to help contextualize the various verses of the Qur'an. It can hopefully help others find linguistically similar verses in the Qur'an to help form a more holistic understanding of its message and meaning.
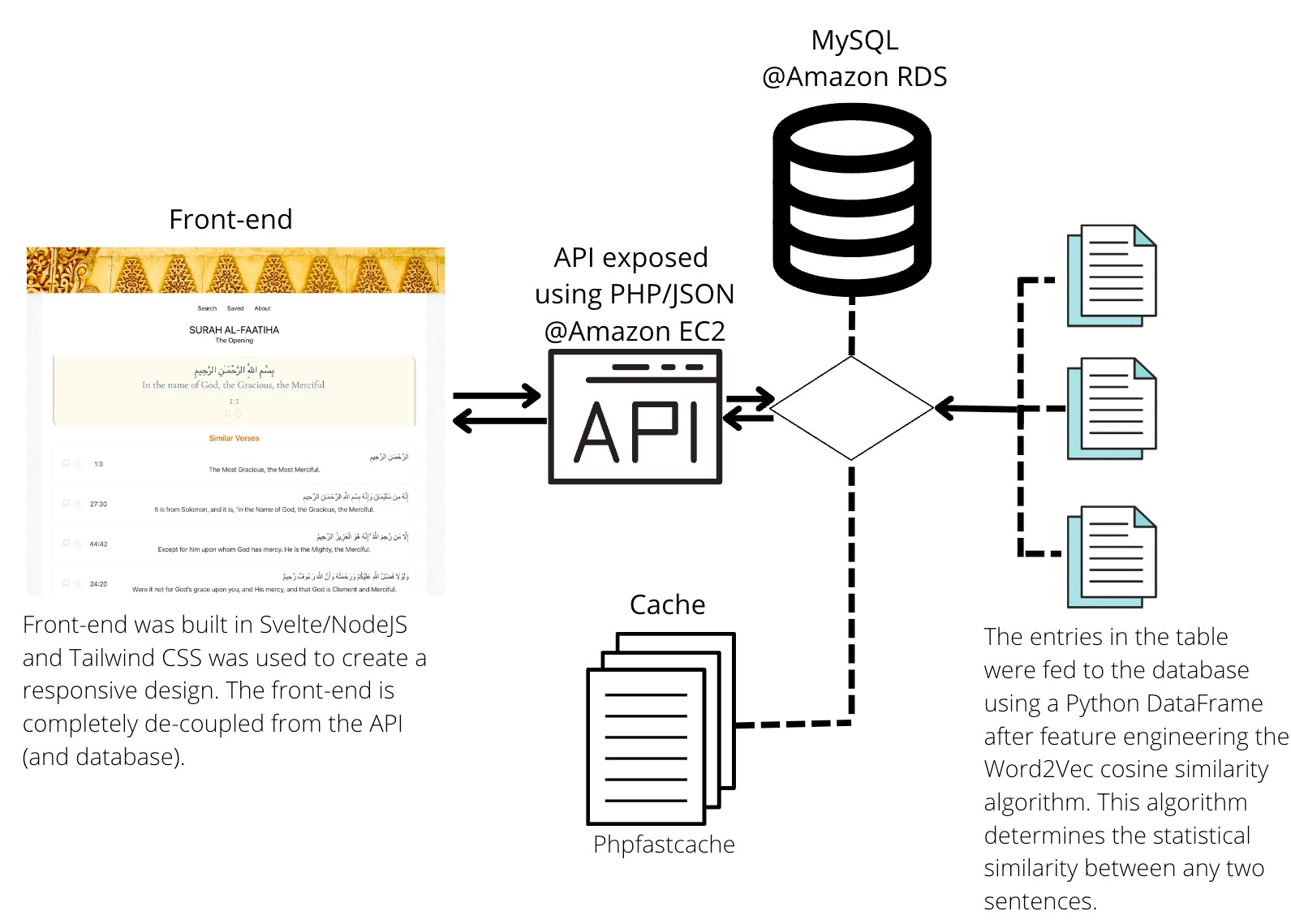
I used a machine learning model known as Word2Vec to find similar verses. A cosine similarity algorithm determed the distance between each verse. This permutation resulted in many million rows of data, which was then stemmed to reduce dimensionality. The final dataset is readable through an API. A cache system was added to enhance load times and reduce expensive calls to the database. The web application accesses this API using a front-end built in Svelte JS. Tailwind CSS was used to create a responsive design.
Front-end code is available on GitHub. Feel free to reach out: Jawad Shuaib.